NVIDIA shared how to run OpenClaw and large language models fully on local systems using GeForce RTX and RTX GPUs as well as DGX Spark. OpenClaw is a local first AI agent that can remember conversations, use file and app context, and extend capabilities through skills. Running the agent with a local LLM reduces cloud costs and keeps personal data on device, while RTX GPU acceleration and DGX Spark hardware help sustain always on performance.
엔비디아가 지포스 RTX·RTX GPU와 DGX 스파크에서 오픈클로와 LLM을 완전한 로컬 환경으로 실행하는 방법을 공개했다.
오픈클로는 사용자의 컴퓨터에서 구동되는 로컬 우선 AI 에이전트다. 대화 내용을 기억하고 맥락에 맞춰 동작을 조정하며, 로컬 환경에서 상시 실행되는 형태로 파일과 앱의 맥락 정보를 활용한다. 스킬을 추가해 기능을 확장하는 구조도 포함한다.
오픈클로는 이메일, 달력, 파일을 활용해 일정 관리와 이메일 초안 작성, 알림 전송, 회의 일정 조율을 수행하는 개인 비서 형태로 사용할 수 있다. 이메일과 메시징 채널을 통해 진행 상황을 점검하고 상태 보고와 후속 조치를 정리하는 프로젝트 관리 용도로도 활용할 수 있다. 인터넷 검색 결과와 로컬 파일을 결합해 보고서를 생성하는 연구 에이전트 시나리오도 포함한다.
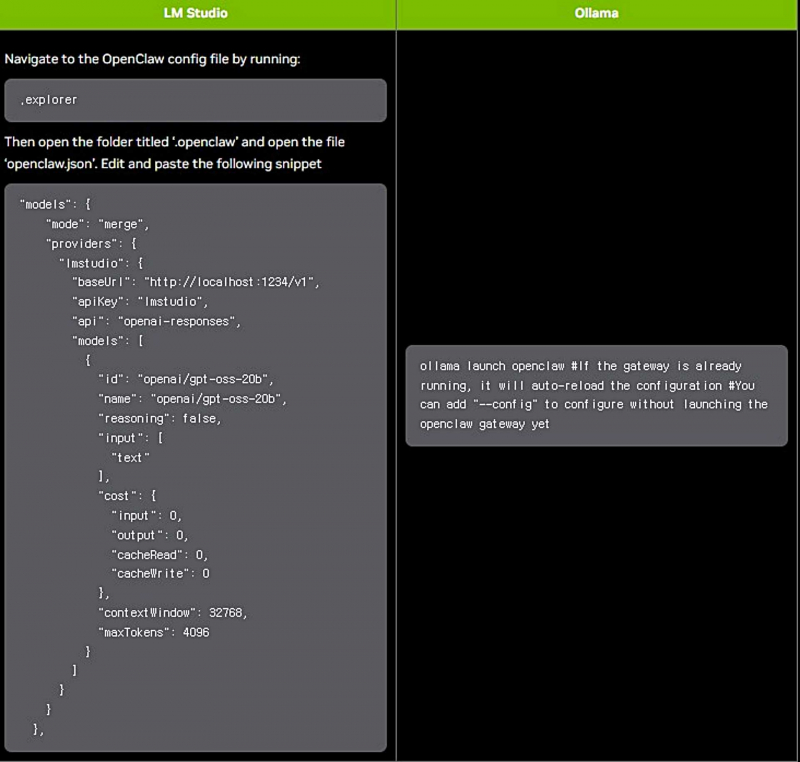
오픈클로는 로컬 또는 클라우드 환경에서 실행 가능한 LLM을 기반으로 동작한다. 클라우드 LLM을 상시 사용하는 방식은 비용 부담이 커질 수 있고 개인 데이터를 업로드해야 하는 상황이 발생할 수 있다. RTX GPU나 DGX 스파크에서 로컬 LLM으로 오픈클로를 구동하면 비용 부담을 줄이면서 개인 데이터가 기기 밖으로 나가지 않도록 운영할 수 있다.
RTX GPU는 텐서 코어와 CUDA 가속을 통해 AI 연산을 지원하며, 오픈클로 실행에 사용되는 올라마와 라마.cpp 같은 도구 구성을 지원한다. DGX 스파크는 상시 구동 환경을 고려한 설계와 128GB 메모리를 기반으로 더 큰 로컬 모델을 실행하는 구성을 제공한다.
